Hello everyone!
Hello everyone!
(please note, this post is a work in progress, and for some reason sometimes the heroku web app is not working. Today, 12/12/18 its working but yesterday it wasn’t, I’m unsure what caused this)
Ever wanted to make graphs a little more interactive? I made these nice looking figures using python recently (https://rafaels-rfm-dashboard.herokuapp.com/). The plotly library is great for making interactive graphs. And, if you want to put them on the internet for easy access, plotly has Dash. Dash is a python framework for making crisp visualizations work on the internet. It’s built on Flask, (also plotly.js +react) and best of all for you unrepentant pythonistas, you don’t even need to know a drop of HTML to get it running.
This post assumes basic python knowledge, as well as understanding of basic RFM customer segmentation. However, you don’t need to know what RFM means to get a lot from this post. I just use the terms without defining them, This post is PLENTY long without going into why or why not RFM and churn are important business metrics.
In the next few paragraphs I’ll walk you through the construction of the plots shown in the gif on the left with python, and deployment on the internet for easy sharing, using  Heroku. Then I’ll talk a bit about things I would like to improve about my implementation.
Heroku. Then I’ll talk a bit about things I would like to improve about my implementation.
All the data and code that made this is up on my github page
First, a quick description of the data, its a set of online retail transactions thats made the rounds for a couple years. It’s been on the UC Irvine machine learning repository, and maybe a year ago kaggle put it up as well. So, finding something new about it would be challenging. But, E-commerce data is usually proprietary, so this data set is not totally worthless. And, it wont require much work to put into plot-able form. I’ll describe some other data sets in later posts and we can look at dealing with real world, dirty data then.
First thing to do is clean the data, get rid of duplicates, errors, and other problematic parts. But see above, it’s actually pretty dang clean to begin with so this step is only important if you are using another data set or need to filter out useless/bad information. Sometimes it can be challenging to get the raw data ready for pandas, but this dataset is almost ready to go, just a couple quick passes to process it. I defined some functions to to do this, and they comprise the first block of code here. Please note, wordpress keeps corrupting the following code, so if it looks wrong, or is missing, please refer to my github page linked above, its all there and working. As of today wordpress seems unhappy for some reason with the import section, so you will have to check my github page if for some reason you need to know which packages I used.
Go ahead and click “expand source” to view the code snippets…
# now to define function to return monthly revenue
def monthly_revenue(arr):
revenue = arr['TotalPrice'].sum()
return revenue
def count_monthly_churn(arr):
return arr['churned'].sum()
def clean_and_preprocess(arr):
# time to start cleaning the data
data = arr.dropna()
# remove returned items
data = data[data['Quantity']>0]
#make column for price total of item cost*Quantity
data['TotalPrice'] = data['UnitPrice'] * data['Quantity']
#make datetime from other datatype
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'])
return data
def make_RFM_churn_df(arr):
#need the final datetime to calculate recency
final_date_time = arr['InvoiceDate'].max()
#make dataframe with some lambda statements about recency and money spent
RFM_table = arr.groupby('CustomerID').agg({'InvoiceDate' : lambda x: (final_date_time - x.max()).days, 'InvoiceNo' : lambda x: len(x), 'TotalPrice' : lambda x: x.sum()})
RFM_table['customer_ID'] = arr['CustomerID'].unique()
RFM_table['InvoiceDate_int'] = RFM_table['InvoiceDate'].astype(int)
RFM_table.rename(columns = {'InvoiceDate_int' : 'recency', 'InvoiceNo' : 'frequency', 'TotalPrice' : 'monetary_value'}, inplace=True)
RFM_table['churned'] = RFM_table['recency'].apply(is_churned)
return RFM_table
Ok, we have the cleaning and processing functions defined. Now we feed in the csv file, turn it into a pandas dataframe (DF or df), and use the functions to output a new dataframe. The new DF is cleaner, and has new columns, recency and frequency per customer, and one with purchase amount in addition to column for number of items and cost per item. This DF will be used to generate the RFM numbers, but it needs to be hacked apart and pieced together into an ugly list before it will work in a graph with monthly updates to Revenue and Churn numbers controlled by a slider bar (more on how and why later.) We also pickle the dataframe (that means writing it to disk.) Why? Although it saves time if we want reopen the project, more importantly we don’t want to make the function do all the processing when its up on heroku. So, we just make the .pkl files and upload them with the code.
# read the csv data and define datatypes to make it faster
data_raw = pd.read_csv("data.csv", encoding="ISO-8859-1", dtype={'CustomerID': str, 'InvoiceNo': str})
# clean the data with clean_and_preprocess funtion
data_cleaned = clean_and_preprocess(data_raw)
# make the datafarme for the RFM plot then pickle it for ease of modifying plot parameters
data_for_plotly = make_RFM_churn_df(data_cleaned)
data_for_plotly.to_pickle('data_for_plotly.pkl')
Now for a couple steps that might seem a little odd, and I admit it seems hacky. But it works, which ultimately is better than a mostly working but perfectly written script. Basically, we need numbers and month names for the updating data with a slider in plotly. So, we make a list containing monthly slices of the main dataframe using pandas “Grouper” along with groupby in a list comprehension. Note: you need InvoiceDate to be in datetime format for this to work. We also make a list of the months by name for 0-12 (Jan to Jan) and a list of the 13 integers 0-12 for zipping things together later. We also do a bad bad thing and define some empty lists outside of a function. This blatant (and willful) style violation is to make sure jupyter doesn’t feed in non-empty lists to later processes. The later processes don’t actually need the lists to run, I used actual error handling (try and except blocks). But if you don’t empty the list when re-running an ipython kernel the data gets piled in and things go haywire. There could be other fixes for this but I haven’t yet gotten around to trying to implement anything else.
# make a list of all the months in the data
list_RFM_months = [g for n, g in data_cleaned.groupby(pd.Grouper(key = 'InvoiceDate', freq = 'M'))]
# we need the names of the months as well for the plot.ly plots
list_of_month_names = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec', 'Jan']
# we'll also need a list of the numbers to zip stuff together later
list_1_to_13 = [ i for i in range(13)]
# we need lists and a dataframe to put a bunch of the data into for making sequential time points. This is
# unnecessary (and also bad and wrong) with the try statements EXCEPT when you run the code repeatedly in a jupyter notebook
# you will get problems with the lists already existing,
# and data doesnt end up organized correctly so we make sure they are empty here
monthly_churn_list = []
monthly_revenue_list = []
massive_revenue_churn_list = []
full_data_frame = pd.DataFrame()
Ok, we have a list with 13 dataframes with monthly data now, and RFM data in a separate DF. We need to extract the monthly revenue and churn data (more on why the way I did this is a not perfect way to calculate churn at the end of the post 🙂 )
We take the list of the DFs sliced by month, and loop over it and apply the count monthly revenue and monthly churn functions… But wait, the list has monthly slices, how to calculate churn without reading data from the last month?
I append the monthly DF to a DF containing all monthly DF’s read so far, then calculate total churn, then subtract total churn from the month before to get churn in that month. Yes it’s ugly, but I didn’t get around to making a better way to calculate churn. If this was production code, I would certainly have spent a lot more time making sure this was done right. But this was more just to crank out some numbers for nice looking graphs and a blog post about plotly, not actionable insight for a business.
Note: the now monthly DF only has revenue and churn, and I zip these together with month name, so its not a DF of ALLLLLL the data, just the aggregate results.
Next, we append the sum-to-date dataframe to (what quickly becomes) a big list of dataframes, [df(Jan),] then [df(Jan), “df(Jan+Feb)] then a list with [df[(Jan), df(Jan&Feb), df(Jan&Feb&Mar)] etc. But wait again! Why make a list with increasingly large dataframes if we already have a year-to-date DF? It turns the slider bar is used to select data, and if you have 1 months worth selected then only a single bar is displayed. Thus an oddly structured list with each member consisting of the previous member with a new month appended. I didn’t use a recursive call to do make the list, but I certainly could have.
Then we zip together (yes another zip) the month numbers to the values of the big list of appended DFs. And in the final data packaging stage, we pickle everything.
for month_data_frame in list_RFM_months:
months_revenue = monthly_revenue(month_data_frame)
print('months revenue = {}'.format(months_revenue))
full_data_frame = full_data_frame.append(month_data_frame)
RFM_data_with_current_month = make_RFM_churn_df(full_data_frame)
this_month_total_churn = count_monthly_churn(RFM_data_with_current_month)
try:
this_month_churn = this_month_total_churn - last_month_total_churn
print('this month churn try loop')
except NameError:
this_month_churn = this_month_total_churn
print('this month churn except loop')
print('this month\'s churn = {}'.format(this_month_churn))
try:
last_month_total_churn += this_month_churn
except NameError:
last_month_total_churn = this_month_churn
try:
monthly_churn_list.append(this_month_churn)
except NameError:
monthly_churn_list = [this_month_churn]
try:
monthly_revenue_list.append(months_revenue)
except NameError:
monthly_revenue_list = [months_revenue]
month_churn_human_readable = [ x * -1 for x in monthly_churn_list]
monthly_revenue_churn_dataframe = pd.DataFrame(list(zip(list_of_month_names, monthly_revenue_list, month_churn_human_readable)), columns = ['Month', 'Revenue', 'Churn'])
massive_revenue_churn_list.append(monthly_revenue_churn_dataframe)
massive_revenue_churn_dataframe = pd.DataFrame(list(zip(list_1_to_13, massive_revenue_churn_list)), columns = ['month_index', 'appended_dataframe'])
with open('massive_revenue_churn_list.pkl', 'wb') as f:
pickle.dump(massive_revenue_churn_list, f)
massive_revenue_churn_dataframe.to_pickle('./massive_revenue_churn_dataframe.pkl')
Awesome. Now on to the Dash and plotly stuff. I’m really liking plotly so far, it’s easy, the documentation is (mostly) good, and it means I don’t have to look at R in the rearview mirror longing for its nice plots. Hey, if you are an R person, there’s even plotly for R. But I digress.
In my github repo this is all in one jupyter notebook, but in production code and for anyone using this post as a tutorial, you should prob just stuff the following code into its own separate script. Otherwise you will hammer through every step of the cleaning arranging each time you call the script. Debugging and perfecting would be time consuming. Also, you don’t want to make heroku (or wherever your code gets deployed) to have to recalculate everything all the time. Just read the pickles as below…
First, we import all the python packages we need. Then we define the flask server, app and the secret key, and import the data to make the graphs. For some reason I couldn’t make heroku happy without this secret key block, the Dash and Heroku instructions weren’t working. Cue 4:15 am panic googling. Thanks to jimmybow for the fix.
import pickle
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.graph_objs as go
import plotly.plotly as py
import plotly.tools
import numpy as np
import time, warnings
import datetime as dt
import pandas as pd
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
from flask import Flask
import os
from dash.dependencies import Input, Output
server = Flask(__name__)
server.secret_key = os.environ.get('secret_key', 'secret')
app = dash.Dash(name = __name__, server = server)
app.config.supress_callback_exceptions = True
with open('massive_revenue_churn_list.pkl', 'rb') as f:
massive_revenue_churn_list = pickle.load(f)
massive_revenue_churn_dataframe = pd.read_pickle('./massive_revenue_churn_dataframe.pkl')
data_for_plotly = pd.read_pickle('./data_for_plotly.pkl')
massive_revenue_churn_dataframe.head()
We start by defining some color defaults. Note they are in dictionary form, as many plotly inputs are. You can pick colors in a variety of ways, I picked from the 140 named colors because I think its easier to think about while staring at code, but if you prefer RGB that works too. I’m unsure if hex colors work. I played a bit with color combinations, and I thought slate grey background with pale turquoise text popped nicely.
The way I wrote the code gets a little spaghetti-ish now. Why? Mostly because I wanted to get a MVP of this post out this week and I put the plots together separately. It’s not unreadably bad, but def something to be fixed later.
EDIT: I fixed the spaghetti issue, thus the following paragraph no longer applies. Basically, I just moved the blocks that these two variables pointed to, and deleted the variables themselves
layout_RFM = (blerp)
and
data_RFM = (derp)
By that I mean I took the (derp) and (blerp) blocks and moved them down top where the variables layout_RFM and data_RFM got called into the
figure = {
section, right below dcc.Graph in the code block 2 sections below. While I could update the code shown to reflect the changes, I’m worried that wordpress will get angry and truncate it the way it did with the first block. So you can crack open a tomato sauce jar and pour it all over this spaghetti code. Actually, that is a bad idea.
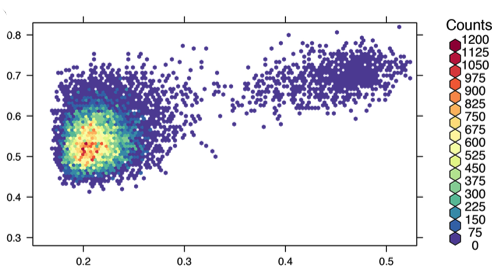
I define a trace, specifically a scatter plot, with plotly.graph_objs, to display each unique customer as a dot, x as recency, y as frequency, and a color scale to show how much moolah they spent over the course of the data set. I used the scale “Picnic” but you could try portland, viridis, blackbody, etc. I also defined the hover text, but the data is a bit dense for this to be an effective thing.
The markers block has all the info for the dots, size, color, outline, and opacity. With dense data like this opaqueness makes it easier to see how dense things actually are, and outlines also help. I used line=0.75 (the line thickness) and line color to be orchid. With size=9 and opacity=0.5 this data seemed easiest to assimilate, but for different data there may be better settings. One could argue that opacity+color scale don’t play well together since it’s hard to see if the darker spots are from overlaid data or different revenue value; and that’s a valid point. But it looks cool and this data isn’t actually important so lets just stick with making it look nicest.
The final block in the following code snippet is just a bit of housekeeping. Labels, typesetting, log scale, etc.
colors = {
'background': 'SlateGray',
'text': 'PaleTurquoise'
}
trace_RFM = go.Scatter(
y = data_for_plotly['frequency'],
x = data_for_plotly['recency'],
text = data_for_plotly['customer_ID'],
hoverinfo = 'text',
mode='markers',
marker=dict(
size=10,
line = dict(
color='LightCoral',
width=1
),
color = data_for_plotly['monetary_value'], #set color equal to a variable
colorbar=dict(
title='Monetary Value',
),
colorscale='Cividis',
showscale=True
)
)
data_RFM = [trace_RFM]
layout_RFM = go.Layout(
title='RFM plot, F vs R (both in a log scale), with M as color, darker color = more customers at that RFM value',
font=dict(family='Courier New, monospace', size=12, color='PaleTurquoise'),
paper_bgcolor='SlateGray',
plot_bgcolor='SlateGray',
xaxis=dict(
title='Recency',
type = 'log',
titlefont=dict(
size=20,
)
),
yaxis=dict(
title='Frequency',
type = 'log',
titlefont=dict(
size=20,
)
)
)
On to the last code snippet… The headline is simple, but then comes the most complex part of the entire script, the slider needs to be defined. More specifically, we need to code what it updates and with what it updates.
First we make the min, the max and the values for the slider bar, then the marks (which for some reason aren’t showing up, another thing to fix).
Then, the app.callback, this is the part of the code that takes reads the slider position, then updates the plot with data. BUT!!! You need to have a function to tell dash what the updated figure looks like. So, remember that month_index zipped into the data frame at the beginning? And the thing getting sliced on the slider I mentioned a few sentences above? These are connected. Basically, the slider selection outputs a string, which then is used to pull a certain slice from the appended_dataframe. This slice has the revenue and churn data from that and all previous months, so if you select the middle you get the data from Jan, Feb, March, April, May and June, but not July, etc. Ok!
Next, the layout of the two updated plots (domain=[0, 0.5] is placing the subplot’s axis between those points), followed by the if __name__ == ‘__main__’ to call the script. If you get errors put port=0 that often fixes ‘port in use’ messages. If that fails, try restarting your jupyter kernel, or picking a port like port=8050 or port=8010
app.layout = html.Div(
style={'fontFamily': 'Courier New, monospace', 'backgroundColor': colors['background']}, children = [
html.H1(
children="Rafael's dashboard,",
style={'textAlign': 'center',
'color': colors['text'],
'fontSize': 32,
'fontFamily': 'Courier New, monospace',
}
),
html.Div(children="use the slider under the first bars to advance the month to show churn and revenue over the course of a year. Note, the axes will align after month 2",
style={'textAlign': 'center',
'color': colors['text'],
'fontSize': 28
}
),
dcc.Graph(id = 'Revenue and Churn with slider'),
dcc.Slider(
id = 'month slider',
min = massive_revenue_churn_dataframe['month_index'].min(),
max = massive_revenue_churn_dataframe['month_index'].max(),
value = massive_revenue_churn_dataframe['month_index'].min(),
marks={str(i): str(i) for i in massive_revenue_churn_dataframe['month_index'].unique()},
),
dcc.Graph(
id = 'RFM',
figure = {
'data': [trace_RFM],
'layout': layout_RFM
})
])
@app.callback(
dash.dependencies.Output('Revenue and Churn with slider', 'figure'),
[dash.dependencies.Input('month slider', 'value')])
def update_figure(selected_index):
appended_dataframe = massive_revenue_churn_list[selected_index]
trace_month_revenue = go.Bar(
x = appended_dataframe['Month'],
y = appended_dataframe['Revenue']
)
trace_month_churn = go.Bar(
x = appended_dataframe['Month'],
y = appended_dataframe['Churn'],
xaxis = 'x2',
yaxis = 'y2'
)
traces = [trace_month_revenue, trace_month_churn]
return {
'data': traces,
'layout': go.Layout(
font=dict(family='Courier New, monospace', size=14, color='PaleTurquoise'),
paper_bgcolor='SlateGray',
plot_bgcolor='SlateGray',
xaxis = dict(
title = 'Monthly Revenue',
domain = [0, 0.45]
),
yaxis = dict(
domain = [0.2, 1]
),
xaxis2 = dict(
title = 'Churn',
domain = [0.55, 1]
),
yaxis2 = dict(
domain = [0, 1],
anchor = 'x2'
)
)
}
if __name__ == '__main__':
app.run_server(port=0)
Weee! The plots are made, all that remains is deployment to Heroku. The following assumes you have a Heroku account, and git. You also need the python packages gunicorn, pip and virtualenv (virtual environment). If you don’t have anaconda, now is the time to get it going to install these.
Fire up ye old terminal emulator, and go to your git directory. The make a new directory,
$ mkdir you_foo_dir_bar
then enter it
$ cd you_foo_dir_bar
Ok, now fire up the virtual environment. It’s a new environment so you need to reinstall whatever python dependencies you need, ie
$ pip install dash
$ pip install dash-renderer
$ pip install dash-core-components
$ pip install dash-html-components
$ pip install plotly
$ pip install gunicorn
and whatever else you need.
Now make a .gitignore file with the lines:
venv
*.pyc
.DS_Store
.env
Now git wont pay attention to these files. Next we make a Procfile with the line:
web gunicorn run:server
This refers gunicorn to the name of the script, “run” . “server” is defined within the script, and it’s a web server. You also need a requirements.txt file, which you populate by piping pip (ha, accidental allitertation) req’s to the file like so:
$ pip freeze > requirements.txt
These are what heroku installs, and if you are like me pip dumps a lot of extraneous package names into this file. In fact, some of them make poor heroku barf and the whole build goes kaput. They also take forever to install when initializing your heroku folder, so go into this file and delete pretty much all of the things other than dash-core-components dash-html-components dash-dependencies flask gunicorn + whatever_other_packages_your_script_calls
Of course, don’t forget the precious script you hacked together. We refer to it as “run” in the Procfile, make sure the names match correctly. NOTE: there is no .py in the Procfile, but .py is on your actual script name.
Now tell heroku to make a new app, the name need not match your script name.
$ heroku create whatever-you-want-to-name-your-app
Stage and commit the directory contents
$ git add .
$ git commit -m “whatever you want to write here about script”
push to heroku:
$ git push heroku master
AAAAAANNNNNDDDDD the moment of truth, start the app on heroku with:
$ heroku ps:scale web=1
And visit the app with (it’s already going at https://whatever-you-named-your-app.herokuapp.com )
$ heroku open
Done.
Ok, so what would I improve? (Edit, and what I DID fix)
The thing that irritates me the most is the slider labels. I ran into trouble with the labels underneath the bars on the plot, since each bar is labeled, each slider notch was getting all the months glued on as well. I suspect adding another column with month names would work.
Another visual issue with the bar plots is how plotly autoformats their width, so they get progressively thinner. This annoys me and I may fix it soon.
I also don’t like how I defined the data and plot params above the plot that they appear below of, in the actual dashboard. Fixing this is actually pretty simple, but I haven’t gone and done it yet.
EDIT: It was a simple fix, as I mentioned above, I just moved some code the variables were filled with down to where the variables were called. The code makes more sense and is easier to read now, yay!
I mentioned defining the lists outside of the functions, and while thats a no-no, I left them in just because it serves a purpose when running the code repeatedly in a jupyter notebook. Its easier than killing the kernel every time. I have given no further thought to how to solve this.
The hover data in the RFM plot is not working correctly, when hovering over a datum mark, it picks some customerID but only one per x value, and there are lots of very closely spaced marks, thus making the hover feature useless. This limits the usefulness of the plot for finding who the best customers are. If this was production code fixing this would be pretty high priority as the plot isn’t very useful without it.
The color scale combined with transparency is not great, its hard to see if a color is from the revenue value, or if there are piles of customerID R&F values making the area dark. While technically this makes the plot less useful, it is aesthetically pleasing. In the future, I would apply a different technique to spread the data, or remove the color scale entirely and use 2 or 3 separate plots to display the relationship between R, F and M.
Finally, the way I defined churn was not perfect. A 45 day churn period may be more accurate, and there are certainly better ways to crunch the numbers than I did to get the churn. If this was production code I would not have done the churn the way I did; my way was pretty sloppy, and churn is a vital metric.
These are topics that should, could, and perhaps will be addressed in the future. (edit, and some were!)
Well, thats it for now!
Best
Rafael